Optimizacija
Vrlo mala promena rutine može nam doneti uštedu u vremenu, koja nam je u ovom slučaju, za filter sa 32 tapa, preko potrebna. Primetićete da rutina ima dva if-a odnosno za filter od 32 tapa cela obrada će imati 2112 grananja. Izbegavanjem if-ova možemo ubrzati funkciju.
Jedan od načina da se izbegnu if-ovi je, da se iskoristi “prirodni” overflow. Naime, ako bi indeks bafera veličine 256 bio tipa neoznačen bajt, ne bi nam trebao if, jer bi se pri uvećanju za jedan, indeksa koji pokazuje na poslednji član bafera desio overflow i indeks bi postao 0 što nam odgovara. Sličnu stvar možemo uraditi za bafere čija je veličina 2^n stim što se ne bi povećavali za jedan već za određenu razliku koja bi bila u obliku 2^m. Primer, ako hoćemo da napravimo bafer veličine 128, a imamo osmobitni indeks, indeks ćemo uvećavati za 2 i onda ćemo ga šiftovati jedno mesto desno kako bi dobili njegovu pravu vrednost. Isto važi i za bafer veičine 64, gde će indeks biti uvećavan za 4 i šiftovan dva mesta desno i tako redom.
Sledeći kod pokazuje kako bi mogli da ubrzamo prethodnu rutinu.
void Filter2(Int16 *input, Int16 *h, Int16 *output,
Int16 NumOfInput, Int16 NumOfCoeff) {
volatile UInt16 i,j;
volatile Int32 y;
static UInt16 xind = 0;
static Int32 x[NumOfCoeff];
volatile UInt16 hind = 0;
ST1_55 |= 0x2000; // Pali LED
for (j=0; j<NumOfInput; j++) {
y=0; // resetuj izlaz
x[xind>>stepen] = input[j]; // ubaci ulaz u baffer
hind = 0 – xind;
for (i=0; i<NumOfCoeff; i++) {
y += h[hind>>stepen] * x[i];
hind += delta;
}
xind += delta;
output[j] = (Int16)(y >> 15); // izlaz Q15
}
ST1_55 &= 0xDFFF; // Gasi LED
}
Važno je da svi indeksi budu neoznačeni brojevi, kako bi pri prekoračenju (overflow-u) dobili 0, a ne negativan broj. Ovom promenom rutine dobili smo ubrzanje od 10% i sada rutina kada obrađuje 32 tapa traje 1180us. Mana ovakvog pristupa je što veličina bafera i delta moraju biti stepen broja 2, a ne bilo koje veličine.
Ova funkcija barata sa dve nove promenljive/koeficijenta:
- delta – za koliko će se uvećati indeks,
- stepen – indeks će biti šiftovan desno “stepen” puta kako bi se dobila realna vrednost indeksa.
U prilogu, na kraju teksta, se nalazi primer rutine za računanje ova dva koeficijenta.
Kao što se vidi iz oba ova koda, ovde ima dosta sabiranja množenja i rada sa kružnim baferima. Tu na scenu stupa DSP koji ima hardverski rešene kružne bafere i MAC (multiply and accumulate - množi i sabiraj sa akumulatorom). Primetite da oba C koda imaju unutrašnju i spoljašnju petlju. U primeru koji sledi prikazano je kako bi taj kod izgledao na Texas Instruments-ovom TMS320C5515 DSP-u.
||RPTBLOCAL loop11 ;start the outer loop
MOV *x_ptr+, *db_ptr ;get next input value
;ist iteration
MPYM *h_ptr+, *db_ptr+, AC0
;inner loop
||RPT inner_cnt
MACM *h_ptr+, *db_ptr+, AC0
;last iteration has different pointer adjustment and rounding
MACMR *h_ptr+, *(db_ptrT1), AC0
;store result to memory
MOV HI(AC0), *r_ptr+ ;store Q15 value to memory
loop1: ;end
Instrukcije koje se pojavljuju u ovom kodu su:
- RPTBLOCAL, RPT – Repeat block – ponavlja blok određen broj puta. Broj ponavljanja je upisan u npr. registar BRC0 ili BRS1,
- MOV – prebacuje sadržaj registra ili memoriske lokacije iz leve u desnu,
- MPYM, MACM, MACMR – multiply and acumulate – množi prvi parametar sa drugim i dodaje ga trecem
Kod radi tako što:
- linija 3 – instrukcija MOV napuni sadržaj pokazivača na delay bafer sadržajem na koji ukazuje pokazivač x_ptr i pomeri x_ptr za jedno mesto. X_ptr ukazuje na odbirak iz ulaznog bafera;
- linija 6 – množi sadržaj pokazivača na koeficijente (h_ptr) i delay bafer (db_ptr), uvećava oba pokazivača za 1 i rezultat množenja smešta u akumulator (AC0);
- linija 10 – množi sadržaj pokazivača na koeficijente (h_ptr) i delay bafer (db_ptr), uvećava oba pokazivača za 1 i rezultat množenja dodaje akumulatoru (AC0). To radi određen broj puta, sve dok je ispunjen uslov za instrukciju RPT (linija 9);
- linija 13 – množi sadržaj pokazivača na koeficijente (h_ptr) i delay bafer (db_ptr), uvećava oba pokazivača za 1 i rezultat množenja dodaje akumulatoru (AC0), pri tome radi podešavanja pointera i zaokruživanja;
- linija 16 – na kraju, sadržaj akumulatora je, zbog množenja dva 16-o bitna broja, postao 32-o bitni broj. Da bi poslali u izlazni bafer 16-o bitni broj, potrebno je da od njega odvojimo najviših 16-bitova. Ova instrukcija odvaja viših 16 bitova, smešta ih na lokaciju na koju ukazuje pozazivač r_ptr i njega pomera za jedno mesto. Sve ovo radi sve dok se uslov za RPTBLOCAL ne ispuni.
Pseudo kod koji bi odgovarao ovom asemblerskom programu bio bi:
loop1 { // izaci ce iz petlje kada procita ceo bafer
x[db_ptr] = input[x_ptr];
ac0 = h[h_ptr++] * x[db_ptr++];
loop2 { // napustiće petlju kada potroši sve koeficijente
ac0 += h[h_ptr++] * x[db_ptr++];
}
ac0 = h[h_ptr++] * x[db_ptrT1];
output[r_ptr++] = Hi(ac0);
}
Vidi se da je pseudo kod veoma sličan našem kodu u C-u. Značajna prednost asemblerskog koda je što je neuporedivo brži od C koda. Naime, za filter od 32 tapa, ovaj kod se izvršava 20us što je 60 puta brže od C-optimizovane rutine.
| Tapovi | Max.vreme | Filter (C) | Filter2 (C) | Fir (asm) |
|---|---|---|---|---|
| 16 | 0.66...ms | 330us | 300us | - |
| 24 | 1ms | 740us | - | - |
| 32 | 1.33...ms | 1310us | 1180us | 20us |
| 48 | 2ms | - | - | 25us |
Napomena: Maximalno vreme je vreme za koje će se napuniti ulazni buffer. Ono je jednako 1/SR*buff_size. SR je sample rate, u načem slučaju je 48kHz, a buff_size je u našem slučaju duplo veći od broja tapova, što je i preporučena veličina. Maximalno vreme je zapravo kašnjenje izlaznog signala u odnosu na ulazni. U audio svetu sve ispod 10ms je prihvatljivo kašnjenje.
U kodu postoje istrukcije koje, na početku i kraju koda, pale i gase LE diodu. Kada dioda jako svetli znači da funkcija ima malo slobodnog vremena tj. da se vreme obrade približava brzini semplovanja. Ako se na LED zakači osciloskop i pogleda signal, on izgleda ovako:
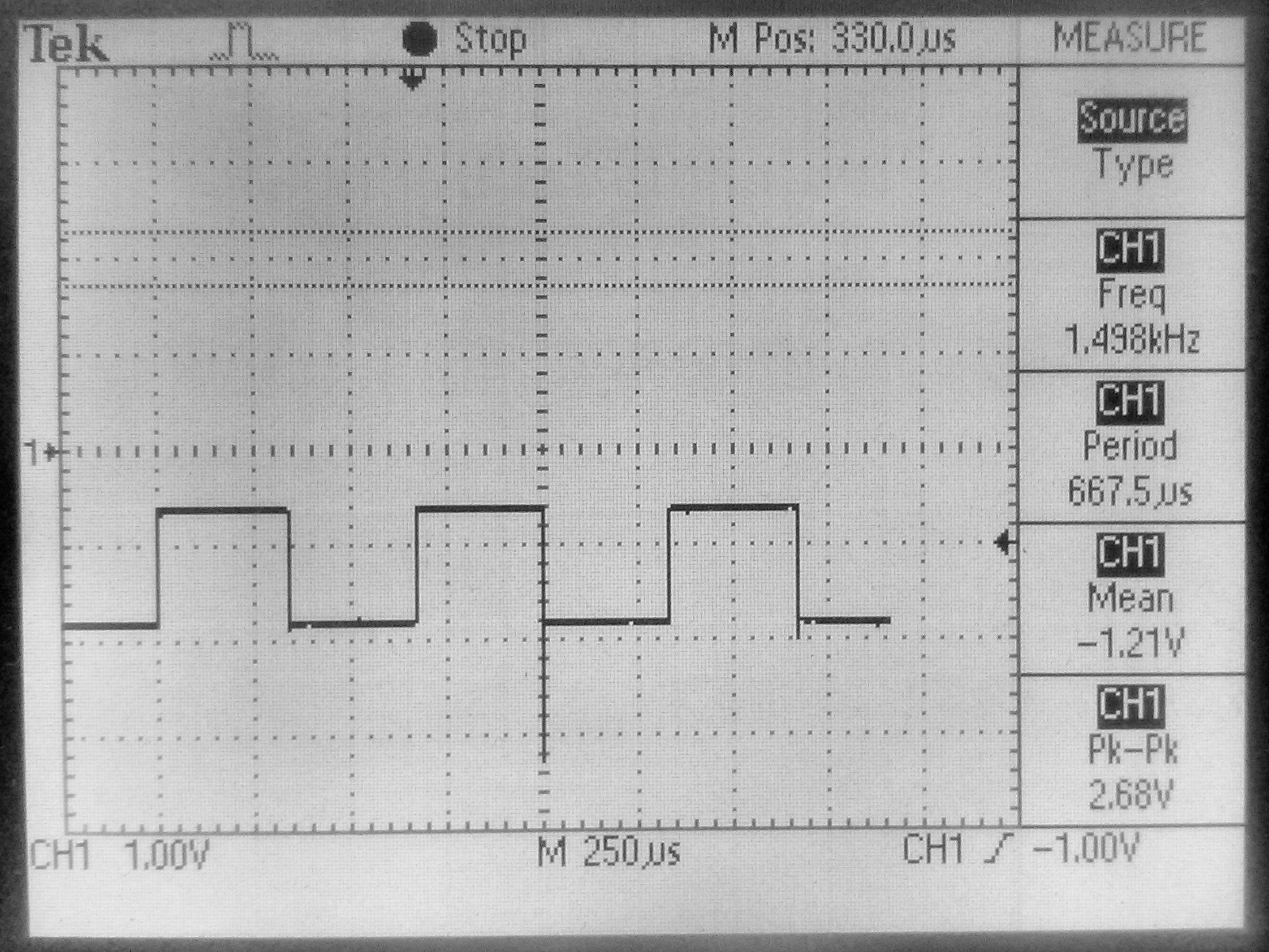
Signal sa LE diode 330us sa periodom od 667us, što odgovara C rutini koja obrađuje 16 tapova.
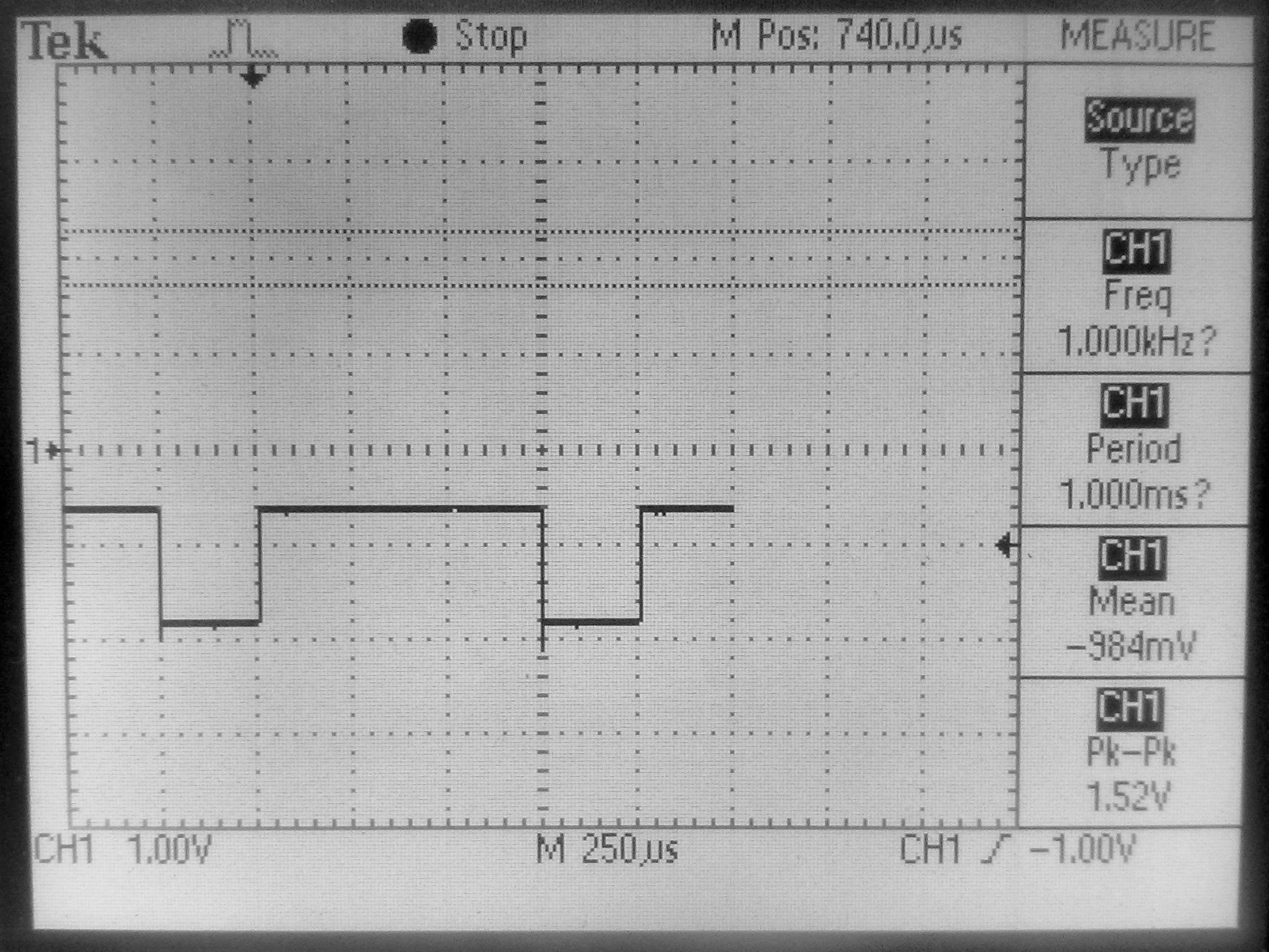
Signal sa LE diode, dužine 740us, sa periodom od 1ms, što odgovara C rutini koja obrađuje 24 tapa.
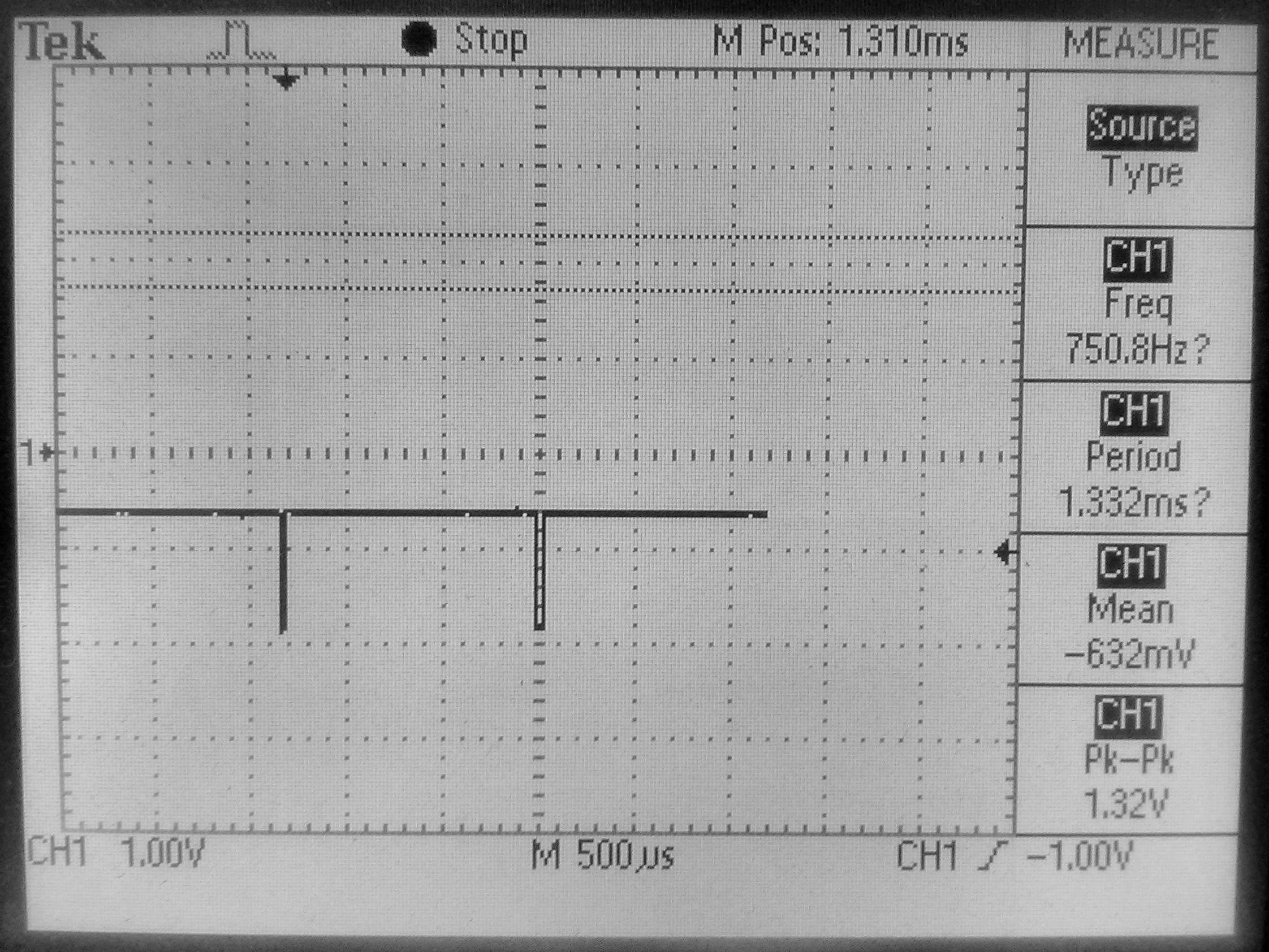 Ovde se vidi da je perioda 1332us, a signal sa LED duzine 1310us, što odgovara C rutini koja obrađuje 32 tapa. Slobodnog vremena skoro da nema.
Ovde se vidi da je perioda 1332us, a signal sa LED duzine 1310us, što odgovara C rutini koja obrađuje 32 tapa. Slobodnog vremena skoro da nema.
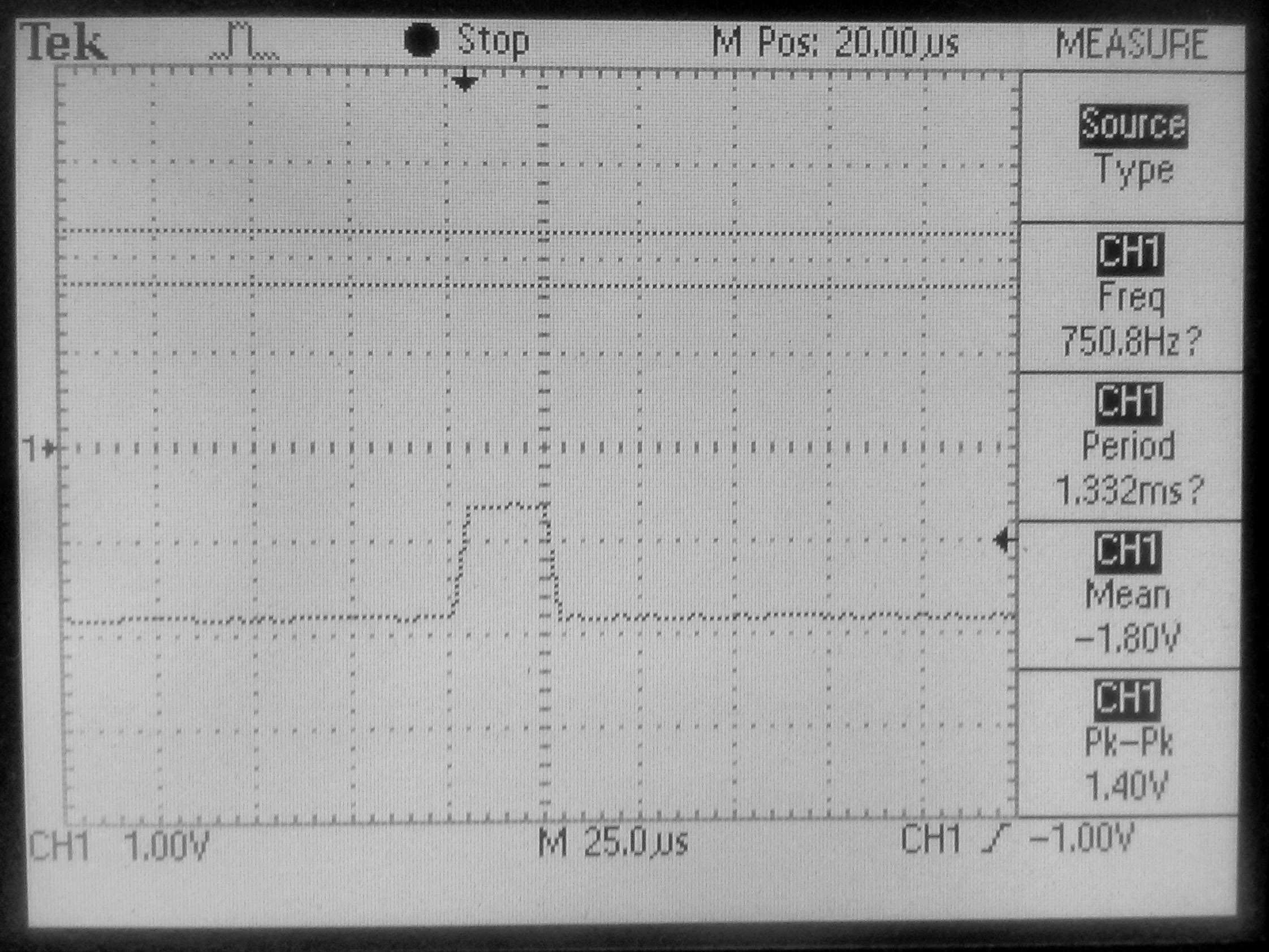
Brzina kojom asemblerska rutina obrađuje 32 tapa. Signal sa LED traje 20us, a cela perioda, tj. ukupnog vremena za obradu ima 1332us, što je odlično.